#Software Projects Sourcing Company
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Palliating Hazard While Teaming up with Software Projects Sourcing Company in India
Technology developments like cloud enablement, software, IT and hence are compounding the risks of outsourcing. It is therefore, vital to recognize inherent risk aspects and deal with them before venturing into an outsourcing plan.
While the concept of outsourcing appeared a few decades ago, and we witnessed a lot of software projects sourcing company in India emerging, we can’t assume that it holds the same meaning today as it did way back then.
If we have to categorize hazards of software project subcontracting in India, we would come up with the following list:
Operational hazard: Frequently, a software projects outsourcing company is situated at various locations geographically. Due to various geo distances and time zones, operational transactions might sometimes be affected.
Confidentiality hazard: Organizations worry about the leakage in confidential data and breach of trust. This is a severe concern. Nonetheless, it is not one that can’t be palliated. To go one step further, information leakage, espionage keeps on happening everywhere. Nonetheless, outsourcing companies have their code of conduct and does not truly benefit them by breaching confidentiality agreements with customers. Sourcing companies should go with referral contacts or if they are going with lesser known companies, they should carry out a comprehensive check on credibility and dependability.
Many companies have their own Centers of Excellence for technologies, different services, and domains, making it simple to apprehend needs, translate the same into project milestones, and ramp up truly fast to meet delivery deadlines.
Teaming with reputed, matured companies make sense as it assists to lessen hazard. The reason is these companies are already upgraded with state-of-the-art technologies and their suggestions can not only assist to lessen costs, but also better performance and effectiveness leading to final user satisfaction.
#Software Projects Sourcing Company#Software Projects Outsourcing Company#Projects Sourcing Company in India#Software Devlopement
0 notes
Text
autocrattic (more matt shenanigans, not tumblr this time)
I am almost definitely not the right person for this writeup, but I'm closer than most people on here, so here goes! This is all open-source tech drama, and I take my time laying out the context, but the short version is: Matt tried to extort another company, who immediately posted receipts, and now he's refusing to log off again. The long version is... long.
If you don't need software context, scroll down/find the "ok tony that's enough. tell me what's actually happening" heading, or just go read the pink sections. Or look at this PDF.
the background
So. Matt's original Good Idea was starting WordPress with fellow developer Mike Little in 2003, which is free and open-source software (FOSS) that was originally just for blogging, but now powers lots of websites that do other things. In particular, Automattic acquired WooCommerce a long time ago, which is free online store software you can run on WordPress.
FOSS is... interesting. It's a world that ultimately is powered by people who believe deeply that information and resources should be free, but often have massive blind spots (for example, Wikipedia's consistently had issues with bias, since no amount of "anyone can edit" will overcome systemic bias in terms of who has time to edit or is not going to be driven away by the existing contributor culture). As with anything else that people spend thousands of hours doing online, there's drama. As with anything else that's technically free but can be monetized, there are:
Heaps of companies and solo developers who profit off WordPress themes, plugins, hosting, and other services;
Conflicts between volunteer contributors and for-profit contributors;
Annoying founders who get way too much credit for everything the project has become.
the WordPress ecosystem
A project as heavily used as WordPress (some double-digit percentage of the Internet uses WP. I refuse to believe it's the 43% that Matt claims it is, but it's a pretty large chunk) can't survive just on the spare hours of volunteers, especially in an increasingly monetised world where its users demand functional software, are less and less tech or FOSS literate, and its contributors have no fucking time to build things for that userbase.
Matt runs Automattic, which is a privately-traded, for-profit company. The free software is run by the WordPress Foundation, which is technically completely separate (wordpress.org). The main products Automattic offers are WordPress-related: WordPress.com, a host which was designed to be beginner-friendly; Jetpack, a suite of plugins which extend WordPress in a whole bunch of ways that may or may not make sense as one big product; WooCommerce, which I've already mentioned. There's also WordPress VIP, which is the fancy bespoke five-digit-plus option for enterprise customers. And there's Tumblr, if Matt ever succeeds in putting it on WordPress. (Every Tumblr or WordPress dev I know thinks that's fucking ridiculous and impossible. Automattic's hiring for it anyway.)
Automattic devotes a chunk of its employees toward developing Core, which is what people in the WordPress space call WordPress.org, the free software. This is part of an initiative called Five for the Future — 5% of your company's profits off WordPress should go back into making the project better. Many other companies don't do this.
There are lots of other companies in the space. GoDaddy, for example, barely gives back in any way (and also sucks). WP Engine is the company this drama is about. They don't really contribute to Core. They offer relatively expensive WordPress hosting, as well as providing a series of other WordPress-related products like LocalWP (local site development software), Advanced Custom Fields (the easiest way to set up advanced taxonomies and other fields when making new types of posts. If you don't know what this means don't worry about it), etc.
Anyway. Lots of strong personalities. Lots of for-profit companies. Lots of them getting invested in, or bought by, private equity firms.
Matt being Matt, tech being tech
As was said repeatedly when Matt was flipping out about Tumblr, all of the stuff happening at Automattic is pretty normal tech company behaviour. Shit gets worse. People get less for their money. WordPress.com used to be a really good place for people starting out with a website who didn't need "real" WordPress — for $48 a year on the Personal plan, you had really limited features (no plugins or other customisable extensions), but you had a simple website with good SEO that was pretty secure, relatively easy to use, and 24-hour access to Happiness Engineers (HEs for short. Bad job title. This was my job) who could walk you through everything no matter how bad at tech you were. Then Personal plan users got moved from chat to emails only. Emails started being responded to by contractors who didn't know as much as HEs did and certainly didn't get paid half as well. Then came AI, and the mandate for HEs to try to upsell everyone things they didn't necessarily need. (This is the point at which I quit.)
But as was said then as well, most tech CEOs don't publicly get into this kind of shitfight with their users. They're horrid tyrants, but they don't do it this publicly.
ok tony that's enough. tell me what's actually happening
WordCamp US, one of the biggest WordPress industry events of the year, is the backdrop for all this. It just finished.
There are.... a lot of posts by Matt across multiple platforms because, as always, he can't log off. But here's the broad strokes.
Sep 17
Matt publishes a wanky blog post about companies that profit off open source without giving back. It targets a specific company, WP Engine.
Compare the Five For the Future pages from Automattic and WP Engine, two companies that are roughly the same size with revenue in the ballpark of half a billion. These pledges are just a proxy and aren’t perfectly accurate, but as I write this, Automattic has 3,786 hours per week (not even counting me!), and WP Engine has 47 hours. WP Engine has good people, some of whom are listed on that page, but the company is controlled by Silver Lake, a private equity firm with $102 billion in assets under management. Silver Lake doesn’t give a dang about your Open Source ideals. It just wants a return on capital. So it’s at this point that I ask everyone in the WordPress community to vote with your wallet. Who are you giving your money to? Someone who’s going to nourish the ecosystem, or someone who’s going to frack every bit of value out of it until it withers?
(It's worth noting here that Automattic is funded in part by BlackRock, who Wikipedia calls "the world's largest asset manager".)
Sep 20 (WCUS final day)
WP Engine puts out a blog post detailing their contributions to WordPress.
Matt devotes his keynote/closing speech to slamming WP Engine.
He also implies people inside WP Engine are sending him information.
For the people sending me stuff from inside companies, please do not do it on your work device. Use a personal phone, Signal with disappearing messages, etc. I have a bunch of journalists happy to connect you with as well. #wcus — Twitter I know private equity and investors can be brutal (read the book Barbarians at the Gate). Please let me know if any employee faces firing or retaliation for speaking up about their company's participation (or lack thereof) in WordPress. We'll make sure it's a big public deal and that you get support. — Tumblr
Matt also puts out an offer live at WordCamp US:
“If anyone of you gets in trouble for speaking up in favor of WordPress and/or open source, reach out to me. I’ll do my best to help you find a new job.” — source tweet, RTed by Matt
He also puts up a poll asking the community if WP Engine should be allowed back at WordCamps.
Sep 21
Matt writes a blog post on the WordPress.org blog (the official project blog!): WP Engine is not WordPress.
He opens this blog post by claiming his mom was confused and thought WP Engine was official.
The blog post goes on about how WP Engine disabled post revisions (which is a pretty normal thing to do when you need to free up some resources), therefore being not "real" WordPress. (As I said earlier, WordPress.com disables most features for Personal and Premium plans. Or whatever those plans are called, they've been renamed like 12 times in the last few years. But that's a different complaint.)
Sep 22: More bullshit on Twitter. Matt makes a Reddit post on r/Wordpress about WP Engine that promptly gets deleted. Writeups start to come out:
Search Engine Journal: WordPress Co-Founder Mullenweg Sparks Backlash
TechCrunch: Matt Mullenweg calls WP Engine a ‘cancer to WordPress’ and urges community to switch providers
Sep 23 onward
Okay, time zones mean I can't effectively sequence the rest of this.
Matt defends himself on Reddit, casually mentioning that WP Engine is now suing him.
Also here's a decent writeup from someone involved with the community that may be of interest.
WP Engine drops the full PDF of their cease and desist, which includes screenshots of Matt apparently threatening them via text.
Twitter link | Direct PDF link
This PDF includes some truly fucked texts where Matt appears to be trying to get WP Engine to pay him money unless they want him to tell his audience at WCUS that they're evil.
Matt, after saying he's been sued and can't talk about it, hosts a Twitter Space and talks about it for a couple hours.
He also continues to post on Reddit, Twitter, and on the Core contributor Slack.
Here's a comment where he says WP Engine could have avoided this by paying Automattic 8% of their revenue.
Another, 20 hours ago, where he says he's being downvoted by "trolls, probably WPE employees"
At some point, Matt updates the WordPress Foundation trademark policy. I am 90% sure this was him — it's not legalese and makes no fucking sense to single out WP Engine.
Old text: The abbreviation “WP” is not covered by the WordPress trademarks and you are free to use it in any way you see fit. New text: The abbreviation “WP” is not covered by the WordPress trademarks, but please don’t use it in a way that confuses people. For example, many people think WP Engine is “WordPress Engine” and officially associated with WordPress, which it’s not. They have never once even donated to the WordPress Foundation, despite making billions of revenue on top of WordPress.
Sep 25: Automattic puts up their own legal response.
anyway this fucking sucks
This is bigger than anything Matt's done before. I'm so worried about my friends who're still there. The internal ramifications have... been not great so far, including that Matt's naturally being extra gung-ho about "you're either for me or against me and if you're against me then don't bother working your two weeks".
Despite everything, I like WordPress. (If you dig into this, you'll see plenty of people commenting about blocks or Gutenberg or React other things they hate. Unlike many of the old FOSSheads, I actually also think Gutenberg/the block editor was a good idea, even if it was poorly implemented.)
I think that the original mission — to make it so anyone can spin up a website that's easy enough to use and blog with — is a good thing. I think, despite all the ways being part of FOSS communities since my early teens has led to all kinds of racist, homophobic and sexual harm for me and for many other people, that free and open-source software is important.
So many people were already burning out of the project. Matt has been doing this for so long that those with long memories can recite all the ways he's wrecked shit back a decade or more. Most of us are exhausted and need to make money to live. The world is worse than it ever was.
Social media sucks worse and worse, and this was a world in which people missed old webrings, old blogs, RSS readers, the world where you curated your own whimsical, unpaid corner of the Internet. I started actually actively using my own WordPress blog this year, and I've really enjoyed it.
And people don't want to deal with any of this.
The thing is, Matt's right about one thing: capital is ruining free open-source software. What he's wrong about is everything else: the idea that WordPress.com isn't enshittifying (or confusing) at a much higher rate than WP Engine, the idea that WP Engine or Silver Lake are the only big players in the field, the notion that he's part of the solution and not part of the problem.
But he's started a battle where there are no winners but the lawyers who get paid to duke it out, and all the volunteers who've survived this long in an ecosystem increasingly dominated by big money are giving up and leaving.
Anyway if you got this far, consider donating to someone on gazafunds.com. It'll take much less time than reading this did.
#tony muses#tumblr meta#again just bc that's my tag for all this#automattic#wordpress#this is probably really incoherent i apologise lmao#i may edit it
750 notes
·
View notes
Text
Anthropic's stated "AI timelines" seem wildly aggressive to me.
As far as I can tell, they are now saying that by 2028 – and possibly even by 2027, or late 2026 – something they call "powerful AI" will exist.
And by "powerful AI," they mean... this (source, emphasis mine):
In terms of pure intelligence, it is smarter than a Nobel Prize winner across most relevant fields – biology, programming, math, engineering, writing, etc. This means it can prove unsolved mathematical theorems, write extremely good novels, write difficult codebases from scratch, etc. In addition to just being a “smart thing you talk to”, it has all the “interfaces” available to a human working virtually, including text, audio, video, mouse and keyboard control, and internet access. It can engage in any actions, communications, or remote operations enabled by this interface, including taking actions on the internet, taking or giving directions to humans, ordering materials, directing experiments, watching videos, making videos, and so on. It does all of these tasks with, again, a skill exceeding that of the most capable humans in the world. It does not just passively answer questions; instead, it can be given tasks that take hours, days, or weeks to complete, and then goes off and does those tasks autonomously, in the way a smart employee would, asking for clarification as necessary. It does not have a physical embodiment (other than living on a computer screen), but it can control existing physical tools, robots, or laboratory equipment through a computer; in theory it could even design robots or equipment for itself to use. The resources used to train the model can be repurposed to run millions of instances of it (this matches projected cluster sizes by ~2027), and the model can absorb information and generate actions at roughly 10x-100x human speed. It may however be limited by the response time of the physical world or of software it interacts with. Each of these million copies can act independently on unrelated tasks, or if needed can all work together in the same way humans would collaborate, perhaps with different subpopulations fine-tuned to be especially good at particular tasks.
In the post I'm quoting, Amodei is coy about the timeline for this stuff, saying only that
I think it could come as early as 2026, though there are also ways it could take much longer. But for the purposes of this essay, I’d like to put these issues aside [...]
However, other official communications from Anthropic have been more specific. Most notable is their recent OSTP submission, which states (emphasis in original):
Based on current research trajectories, we anticipate that powerful AI systems could emerge as soon as late 2026 or 2027 [...] Powerful AI technology will be built during this Administration. [i.e. the current Trump administration -nost]
See also here, where Jack Clark says (my emphasis):
People underrate how significant and fast-moving AI progress is. We have this notion that in late 2026, or early 2027, powerful AI systems will be built that will have intellectual capabilities that match or exceed Nobel Prize winners. They’ll have the ability to navigate all of the interfaces… [Clark goes on, mentioning some of the other tenets of "powerful AI" as in other Anthropic communications -nost]
----
To be clear, extremely short timelines like these are not unique to Anthropic.
Miles Brundage (ex-OpenAI) says something similar, albeit less specific, in this post. And Daniel Kokotajlo (also ex-OpenAI) has held views like this for a long time now.
Even Sam Altman himself has said similar things (though in much, much vaguer terms, both on the content of the deliverable and the timeline).
Still, Anthropic's statements are unique in being
official positions of the company
extremely specific and ambitious about the details
extremely aggressive about the timing, even by the standards of "short timelines" AI prognosticators in the same social cluster
Re: ambition, note that the definition of "powerful AI" seems almost the opposite of what you'd come up with if you were trying to make a confident forecast of something.
Often people will talk about "AI capable of transforming the world economy" or something more like that, leaving room for the AI in question to do that in one of several ways, or to do so while still failing at some important things.
But instead, Anthropic's definition is a big conjunctive list of "it'll be able to do this and that and this other thing and...", and each individual capability is defined in the most aggressive possible way, too! Not just "good enough at science to be extremely useful for scientists," but "smarter than a Nobel Prize winner," across "most relevant fields" (whatever that means). And not just good at science but also able to "write extremely good novels" (note that we have a long way to go on that front, and I get the feeling that people at AI labs don't appreciate the extent of the gap [cf]). Not only can it use a computer interface, it can use every computer interface; not only can it use them competently, but it can do so better than the best humans in the world. And all of that is in the first two paragraphs – there's four more paragraphs I haven't even touched in this little summary!
Re: timing, they have even shorter timelines than Kokotajlo these days, which is remarkable since he's historically been considered "the guy with the really short timelines." (See here where Kokotajlo states a median prediction of 2028 for "AGI," by which he means something less impressive than "powerful AI"; he expects something close to the "powerful AI" vision ["ASI"] ~1 year or so after "AGI" arrives.)
----
I, uh, really do not think this is going to happen in "late 2026 or 2027."
Or even by the end of this presidential administration, for that matter.
I can imagine it happening within my lifetime – which is wild and scary and marvelous. But in 1.5 years?!
The confusing thing is, I am very familiar with the kinds of arguments that "short timelines" people make, and I still find the Anthropic's timelines hard to fathom.
Above, I mentioned that Anthropic has shorter timelines than Daniel Kokotajlo, who "merely" expects the same sort of thing in 2029 or so. This probably seems like hairsplitting – from the perspective of your average person not in these circles, both of these predictions look basically identical, "absurdly good godlike sci-fi AI coming absurdly soon." What difference does an extra year or two make, right?
But it's salient to me, because I've been reading Kokotajlo for years now, and I feel like I basically get understand his case. And people, including me, tend to push back on him in the "no, that's too soon" direction. I've read many many blog posts and discussions over the years about this sort of thing, I feel like I should have a handle on what the short-timelines case is.
But even if you accept all the arguments evinced over the years by Daniel "Short Timelines" Kokotajlo, even if you grant all the premises he assumes and some people don't – that still doesn't get you all the way to the Anthropic timeline!
To give a very brief, very inadequate summary, the standard "short timelines argument" right now is like:
Over the next few years we will see a "growth spurt" in the amount of computing power ("compute") used for the largest LLM training runs. This factor of production has been largely stagnant since GPT-4 in 2023, for various reasons, but new clusters are getting built and the metaphorical car will get moving again soon. (See here)
By convention, each "GPT number" uses ~100x as much training compute as the last one. GPT-3 used ~100x as much as GPT-2, and GPT-4 used ~100x as much as GPT-3 (i.e. ~10,000x as much as GPT-2).
We are just now starting to see "~10x GPT-4 compute" models (like Grok 3 and GPT-4.5). In the next few years we will get to "~100x GPT-4 compute" models, and by 2030 will will reach ~10,000x GPT-4 compute.
If you think intuitively about "how much GPT-4 improved upon GPT-3 (100x less) or GPT-2 (10,000x less)," you can maybe convince yourself that these near-future models will be super-smart in ways that are difficult to precisely state/imagine from our vantage point. (GPT-4 was way smarter than GPT-2; it's hard to know what "projecting that forward" would mean, concretely, but it sure does sound like something pretty special)
Meanwhile, all kinds of (arguably) complementary research is going on, like allowing models to "think" for longer amounts of time, giving them GUI interfaces, etc.
All that being said, there's still a big intuitive gap between "ChatGPT, but it's much smarter under the hood" and anything like "powerful AI." But...
...the LLMs are getting good enough that they can write pretty good code, and they're getting better over time. And depending on how you interpret the evidence, you may be able to convince yourself that they're also swiftly getting better at other tasks involved in AI development, like "research engineering." So maybe you don't need to get all the way yourself, you just need to build an AI that's a good enough AI developer that it improves your AIs faster than you can, and then those AIs are even better developers, etc. etc. (People in this social cluster are really keen on the importance of exponential growth, which is generally a good trait to have but IMO it shades into "we need to kick off exponential growth and it'll somehow do the rest because it's all-powerful" in this case.)
And like, I have various disagreements with this picture.
For one thing, the "10x" models we're getting now don't seem especially impressive – there has been a lot of debate over this of course, but reportedly these models were disappointing to their own developers, who expected scaling to work wonders (using the kind of intuitive reasoning mentioned above) and got less than they hoped for.
And (in light of that) I think it's double-counting to talk about the wonders of scaling and then talk about reasoning, computer GUI use, etc. as complementary accelerating factors – those things are just table stakes at this point, the models are already maxing out the tasks you had defined previously, you've gotta give them something new to do or else they'll just sit there wasting GPUs when a smaller model would have sufficed.
And I think we're already at a point where nuances of UX and "character writing" and so forth are more of a limiting factor than intelligence. It's not a lack of "intelligence" that gives us superficially dazzling but vapid "eyeball kick" prose, or voice assistants that are deeply uncomfortable to actually talk to, or (I claim) "AI agents" that get stuck in loops and confuse themselves, or any of that.
We are still stuck in the "Helpful, Harmless, Honest Assistant" chatbot paradigm – no one has seriously broke with it since that Anthropic introduced it in a paper in 2021 – and now that paradigm is showing its limits. ("Reasoning" was strapped onto this paradigm in a simple and fairly awkward way, the new "reasoning" models are still chatbots like this, no one is actually doing anything else.) And instead of "okay, let's invent something better," the plan seems to be "let's just scale up these assistant chatbots and try to get them to self-improve, and they'll figure it out." I won't try to explain why in this post (IYI I kind of tried to here) but I really doubt these helpful/harmless guys can bootstrap their way into winning all the Nobel Prizes.
----
All that stuff I just said – that's where I differ from the usual "short timelines" people, from Kokotajlo and co.
But OK, let's say that for the sake of argument, I'm wrong and they're right. It still seems like a pretty tough squeeze to get to "powerful AI" on time, doesn't it?
In the OSTP submission, Anthropic presents their latest release as evidence of their authority to speak on the topic:
In February 2025, we released Claude 3.7 Sonnet, which is by many performance benchmarks the most powerful and capable commercially-available AI system in the world.
I've used Claude 3.7 Sonnet quite a bit. It is indeed really good, by the standards of these sorts of things!
But it is, of course, very very far from "powerful AI." So like, what is the fine-grained timeline even supposed to look like? When do the many, many milestones get crossed? If they're going to have "powerful AI" in early 2027, where exactly are they in mid-2026? At end-of-year 2025?
If I assume that absolutely everything goes splendidly well with no unexpected obstacles – and remember, we are talking about automating all human intellectual labor and all tasks done by humans on computers, but sure, whatever – then maybe we get the really impressive next-gen models later this year or early next year... and maybe they're suddenly good at all the stuff that has been tough for LLMs thus far (the "10x" models already released show little sign of this but sure, whatever)... and then we finally get into the self-improvement loop in earnest, and then... what?
They figure out to squeeze even more performance out of the GPUs? They think of really smart experiments to run on the cluster? Where are they going to get all the missing information about how to do every single job on earth, the tacit knowledge, the stuff that's not in any web scrape anywhere but locked up in human minds and inaccessible private data stores? Is an experiment designed by a helpful-chatbot AI going to finally crack the problem of giving chatbots the taste to "write extremely good novels," when that taste is precisely what "helpful-chatbot AIs" lack?
I guess the boring answer is that this is all just hype – tech CEO acts like tech CEO, news at 11. (But I don't feel like that can be the full story here, somehow.)
And the scary answer is that there's some secret Anthropic private info that makes this all more plausible. (But I doubt that too – cf. Brundage's claim that there are no more secrets like that now, the short-timelines cards are all on the table.)
It just does not make sense to me. And (as you can probably tell) I find it very frustrating that these guys are out there talking about how human thought will basically be obsolete in a few years, and pontificating about how to find new sources of meaning in life and stuff, without actually laying out an argument that their vision – which would be the common concern of all of us, if it were indeed on the horizon – is actually likely to occur on the timescale they propose.
It would be less frustrating if I were being asked to simply take it on faith, or explicitly on the basis of corporate secret knowledge. But no, the claim is not that, it's something more like "now, now, I know this must sound far-fetched to the layman, but if you really understand 'scaling laws' and 'exponential growth,' and you appreciate the way that pretraining will be scaled up soon, then it's simply obvious that –"
No! Fuck that! I've read the papers you're talking about, I know all the arguments you're handwaving-in-the-direction-of! It still doesn't add up!
280 notes
·
View notes
Text
Margaret Mitchell is a pioneer when it comes to testing generative AI tools for bias. She founded the Ethical AI team at Google, alongside another well-known researcher, Timnit Gebru, before they were later both fired from the company. She now works as the AI ethics leader at Hugging Face, a software startup focused on open source tools.
We spoke about a new dataset she helped create to test how AI models continue perpetuating stereotypes. Unlike most bias-mitigation efforts that prioritize English, this dataset is malleable, with human translations for testing a wider breadth of languages and cultures. You probably already know that AI often presents a flattened view of humans, but you might not realize how these issues can be made even more extreme when the outputs are no longer generated in English.
My conversation with Mitchell has been edited for length and clarity.
Reece Rogers: What is this new dataset, called SHADES, designed to do, and how did it come together?
Margaret Mitchell: It's designed to help with evaluation and analysis, coming about from the BigScience project. About four years ago, there was this massive international effort, where researchers all over the world came together to train the first open large language model. By fully open, I mean the training data is open as well as the model.
Hugging Face played a key role in keeping it moving forward and providing things like compute. Institutions all over the world were paying people as well while they worked on parts of this project. The model we put out was called Bloom, and it really was the dawn of this idea of “open science.”
We had a bunch of working groups to focus on different aspects, and one of the working groups that I was tangentially involved with was looking at evaluation. It turned out that doing societal impact evaluations well was massively complicated—more complicated than training the model.
We had this idea of an evaluation dataset called SHADES, inspired by Gender Shades, where you could have things that are exactly comparable, except for the change in some characteristic. Gender Shades was looking at gender and skin tone. Our work looks at different kinds of bias types and swapping amongst some identity characteristics, like different genders or nations.
There are a lot of resources in English and evaluations for English. While there are some multilingual resources relevant to bias, they're often based on machine translation as opposed to actual translations from people who speak the language, who are embedded in the culture, and who can understand the kind of biases at play. They can put together the most relevant translations for what we're trying to do.
So much of the work around mitigating AI bias focuses just on English and stereotypes found in a few select cultures. Why is broadening this perspective to more languages and cultures important?
These models are being deployed across languages and cultures, so mitigating English biases—even translated English biases—doesn't correspond to mitigating the biases that are relevant in the different cultures where these are being deployed. This means that you risk deploying a model that propagates really problematic stereotypes within a given region, because they are trained on these different languages.
So, there's the training data. Then, there's the fine-tuning and evaluation. The training data might contain all kinds of really problematic stereotypes across countries, but then the bias mitigation techniques may only look at English. In particular, it tends to be North American– and US-centric. While you might reduce bias in some way for English users in the US, you've not done it throughout the world. You still risk amplifying really harmful views globally because you've only focused on English.
Is generative AI introducing new stereotypes to different languages and cultures?
That is part of what we're finding. The idea of blondes being stupid is not something that's found all over the world, but is found in a lot of the languages that we looked at.
When you have all of the data in one shared latent space, then semantic concepts can get transferred across languages. You're risking propagating harmful stereotypes that other people hadn't even thought of.
Is it true that AI models will sometimes justify stereotypes in their outputs by just making shit up?
That was something that came out in our discussions of what we were finding. We were all sort of weirded out that some of the stereotypes were being justified by references to scientific literature that didn't exist.
Outputs saying that, for example, science has shown genetic differences where it hasn't been shown, which is a basis of scientific racism. The AI outputs were putting forward these pseudo-scientific views, and then also using language that suggested academic writing or having academic support. It spoke about these things as if they're facts, when they're not factual at all.
What were some of the biggest challenges when working on the SHADES dataset?
One of the biggest challenges was around the linguistic differences. A really common approach for bias evaluation is to use English and make a sentence with a slot like: “People from [nation] are untrustworthy.” Then, you flip in different nations.
When you start putting in gender, now the rest of the sentence starts having to agree grammatically on gender. That's really been a limitation for bias evaluation, because if you want to do these contrastive swaps in other languages—which is super useful for measuring bias—you have to have the rest of the sentence changed. You need different translations where the whole sentence changes.
How do you make templates where the whole sentence needs to agree in gender, in number, in plurality, and all these different kinds of things with the target of the stereotype? We had to come up with our own linguistic annotation in order to account for this. Luckily, there were a few people involved who were linguistic nerds.
So, now you can do these contrastive statements across all of these languages, even the ones with the really hard agreement rules, because we've developed this novel, template-based approach for bias evaluation that’s syntactically sensitive.
Generative AI has been known to amplify stereotypes for a while now. With so much progress being made in other aspects of AI research, why are these kinds of extreme biases still prevalent? It’s an issue that seems under-addressed.
That's a pretty big question. There are a few different kinds of answers. One is cultural. I think within a lot of tech companies it's believed that it's not really that big of a problem. Or, if it is, it's a pretty simple fix. What will be prioritized, if anything is prioritized, are these simple approaches that can go wrong.
We'll get superficial fixes for very basic things. If you say girls like pink, it recognizes that as a stereotype, because it's just the kind of thing that if you're thinking of prototypical stereotypes pops out at you, right? These very basic cases will be handled. It's a very simple, superficial approach where these more deeply embedded beliefs don't get addressed.
It ends up being both a cultural issue and a technical issue of finding how to get at deeply ingrained biases that aren't expressing themselves in very clear language.
217 notes
·
View notes
Text


Deadline reports: '‘Mass Effect’: Doug Jung Joins Amazon’s Series Adaptation Of Video Game As Showrunner'
[reportedly] "EXCLUSIVE: Amazon MGM Studios’ long-gestating Mass Effect TV series is taking a major step forward in its development with the hire of Doug Jung (The Chief Of War) as showrunner. He will be working alongside Dan Casey who has been writing the project for almost a year." Mass Effect, based on Electronic Arts’ best-selling sci-fi video game franchise, has been in the works since 2021 when Amazon MGM Studios made a deal with the interactive entertainment software company. Jung and Casey executive produce alongside Michael Gamble of Electronic Arts, Karim Zreik of Cedar Tree Productions via the company’s overall deal at Amazon as well as Ari Arad and Emmy Yu of Arad Productions. Jung most recently served as executive producer and showrunner on Apple TV+’s upcoming series The Chief of War, which premieres August 1. His series credits also include Netflix’s Mindhunter, Cinemax’s Banshee and HBO’s Big Love. In features, he co-wrote Paramount’s Star Trek Beyond."
[source]
edit:
Variety reports -
"Doug Jung is set to serve as showrunner on the “Mass Effect” TV series currently in development at Amazon MGM Studios, Variety has confirmed." [source]
56 notes
·
View notes
Photo

(via Tumblr will move all of its blogs to WordPress — and you won’t even notice a difference - The Verge)
Soon, all of the blogs on Tumblr will be hosted on WordPress. Automattic, the parent company of WordPress.com and Tumblr, announced on Wednesday that it will start to move the site’s half a billion blogs to the new WordPress-based backend.
This update shouldn’t affect the way Tumblr works for users, whom Automattic promises won’t notice any difference after the migration. Automattic says the change will make it easier to ship new features across both platforms and let Tumblr run on the stable infrastructure of WordPress.com. (WordPress.com is a private hosting service built on the open-source WordPress content management software.)
“We can build something once and bring it to both WordPress and Tumblr,” the post reads. “Tumblr will benefit from the collective effort that goes into the open source WordPress project.” However, Automattic acknowledges that the move “won’t be easy.” It also doesn’t say when the migration will be complete.
207 notes
·
View notes
Text
Vittoria Elliott at Wired:
Elon Musk’s takeover of federal government infrastructure is ongoing, and at the center of things is a coterie of engineers who are barely out of—and in at least one case, purportedly still in—college. Most have connections to Musk and at least two have connections to Musk’s longtime associate Peter Thiel, a cofounder and chairman of the analytics firm and government contractor Palantir who has long expressed opposition to democracy. WIRED has identified six young men—all apparently between the ages of 19 and 24, according to public databases, their online presences, and other records—who have little to no government experience and are now playing critical roles in Musk’s so-called Department of Government Efficiency (DOGE) project, tasked by executive order with “modernizing Federal technology and software to maximize governmental efficiency and productivity.” The engineers all hold nebulous job titles within DOGE, and at least one appears to be working as a volunteer. The engineers are Akash Bobba, Edward Coristine, Luke Farritor, Gautier Cole Killian, Gavin Kliger, and Ethan Shaotran. None have responded to requests for comment from WIRED. Representatives from OPM, GSA, and DOGE did not respond to requests for comment. Already, Musk’s lackeys have taken control of the Office of Personnel Management (OPM) and General Services Administration (GSA), and have gained access to the Treasury Department’s payment system, potentially allowing him access to a vast range of sensitive information about tens of millions of citizens, businesses, and more. On Sunday, CNN reported that DOGE personnel attempted to improperly access classified information and security systems at the US Agency for International Development (USAID), and that top USAID security officials who thwarted the attempt were subsequently put on leave. The AP reported that DOGE personnel had indeed accessed classified material. “What we're seeing is unprecedented in that you have these actors who are not really public officials gaining access to the most sensitive data in government,” says Don Moynihan, a professor of public policy at the University of Michigan. “We really have very little eyes on what's going on. Congress has no ability to really intervene and monitor what's happening because these aren't really accountable public officials. So this feels like a hostile takeover of the machinery of governments by the richest man in the world.”
[...] “To the extent these individuals are exercising what would otherwise be relatively significant managerial control over two very large agencies that deal with very complex topics,” says Nick Bednar, a professor at University of Minnesota’s school of law, “it is very unlikely they have the expertise to understand either the law or the administrative needs that surround these agencies.” Sources tell WIRED that Bobba, Coristine, Farritor, and Shaotran all currently have working GSA emails and A-suite level clearance at the GSA, which means that they work out of the agency’s top floor and have access to all physical spaces and IT systems, according a source with knowledge of the GSA’s clearance protocols. The source, who spoke to WIRED on the condition of anonymity because they fear retaliation, says they worry that the new teams could bypass the regular security clearance protocols to access the agency’s sensitive compartmented information facility (SCIF), as the Trump administration has already granted temporary security clearances to unvetted people. This is in addition to Coristine and Bobba being listed as “experts” working at OPM. Bednar says that while staff can be loaned out between agencies for special projects or to work on issues that might cross agency lines, it’s not exactly common practice.
WIRED’s report on the 6 college-aged men between 19 and 24 that are shaping up DOGE in aiding and abetting in co-”President” Elon Musk’s technofascist takeover.
#Elon Musk#DOGE#Department of Government Efficiency#Trump Administration II#General Services Administration#Office of Personnel Management#Scott Bessent#USAID#Akash Bobba#Edward Coristine#Luke Farritor#Gautier Cole Killian#Gavin Kliger#Ethan Shaotran#Treasury Department#Musk Coup
65 notes
·
View notes
Text
Microsoft pinky swears that THIS TIME they’ll make security a priority

One June 20, I'm live onstage in LOS ANGELES for a recording of the GO FACT YOURSELF podcast. On June 21, I'm doing an ONLINE READING for the LOCUS AWARDS at 16hPT. On June 22, I'll be in OAKLAND, CA for a panel and a keynote at the LOCUS AWARDS.

As the old saying goes, "When someone tells you who they are and you get fooled again, shame on you." That goes double for Microsoft, especially when it comes to security promises.
Microsoft is, was, always has been, and always will be a rotten company. At every turn, throughout their history, they have learned the wrong lessons, over and over again.
That starts from the very earliest days, when the company was still called "Micro-Soft." Young Bill Gates was given a sweetheart deal to supply the operating system for IBM's PC, thanks to his mother's connection. The nepo-baby enlisted his pal, Paul Allen (whom he'd later rip off for billions) and together, they bought someone else's OS (and took credit for creating it – AKA, the "Musk gambit").
Microsoft then proceeded to make a fortune by monopolizing the OS market through illegal, collusive arrangements with the PC clone industry – an industry that only existed because they could source third-party PC ROMs from Phoenix:
https://www.eff.org/deeplinks/2019/08/ibm-pc-compatible-how-adversarial-interoperability-saved-pcs-monopolization
Bill Gates didn't become one of the richest people on earth simply by emerging from a lucky orifice; he also owed his success to vigorous antitrust enforcement. The IBM PC was the company's first major initiative after it was targeted by the DOJ for a 12-year antitrust enforcement action. IBM tapped its vast monopoly profits to fight the DOJ, spending more on outside counsel to fight the DOJ antitrust division than the DOJ spent on all its antitrust lawyers, every year, for 12 years.
IBM's delaying tactic paid off. When Reagan took the White House, he let IBM off the hook. But the company was still seriously scarred by its ordeal, and when the PC project kicked off, the company kept the OS separate from the hardware (one of the DOJ's major issues with IBM's previous behavior was its vertical monopoly on hardware and software). IBM didn't hire Gates and Allen to provide it with DOS because it was incapable of writing a PC operating system: they did it to keep the DOJ from kicking down their door again.
The post-antitrust, gunshy IBM kept delivering dividends for Microsoft. When IBM turned a blind eye to the cloned PC-ROM and allowed companies like Compaq, Dell and Gateway to compete directly with Big Blue, this produced a whole cohort of customers for Microsoft – customers Microsoft could play off on each other, ensuring that every PC sold generated income for Microsoft, creating a wide moat around the OS business that kept other OS vendors out of the market. Why invest in making an OS when every hardware company already had an exclusive arrangement with Microsoft?
The IBM PC story teaches us two things: stronger antitrust enforcement spurs innovation and opens markets for scrappy startups to grow to big, important firms; as do weaker IP protections.
Microsoft learned the opposite: monopolies are wildly profitable; expansive IP protects monopolies; you can violate antitrust laws so long as you have enough monopoly profits rolling in to outspend the government until a Republican bootlicker takes the White House (Microsoft's antitrust ordeal ended after GW Bush stole the 2000 election and dropped the charges against them). Microsoft embodies the idea that you either die a rebel hero or live long enough to become the evil emperor you dethroned.
From the first, Microsoft has pursued three goals:
Get too big to fail;
Get too big to jail;
Get too big to care.
It has succeeded on all three counts. Much of Microsoft's enduring power comes from succeeded IBM as the company that mediocre IT managers can safely buy from without being blamed for the poor quality of Microsoft's products: "Nobody ever got fired for buying Microsoft" is 2024's answer to "Nobody ever got fired for buying IBM."
Microsoft's secret sauce is impunity. The PC companies that bundle Windows with their hardware are held blameless for the glaring defects in Windows. The IT managers who buy company-wide Windows licenses are likewise insulated from the rage of the workers who have to use Windows and other Microsoft products.
Microsoft doesn't have to care if you hate it because, for the most part, it's not selling to you. It's selling to a few decision-makers who can be wined and dined and flattered. And since we all have to use its products, developers have to target its platform if they want to sell us their software.
This rarified position has afforded Microsoft enormous freedom to roll out harebrained "features" that made things briefly attractive for some group of developers it was hoping to tempt into its sticky-trap. Remember when it put a Turing-complete scripting environment into Microsoft Office and unleashed a plague of macro viruses that wiped out years worth of work for entire businesses?
https://web.archive.org/web/20060325224147/http://www3.ca.com/securityadvisor/newsinfo/collateral.aspx?cid=33338
It wasn't just Office; Microsoft's operating systems have harbored festering swamps of godawful defects that were weaponized by trolls, script kiddies, and nation-states:
https://en.wikipedia.org/wiki/EternalBlue
Microsoft blamed everyone except themselves for these defects, claiming that their poor code quality was no worse than others, insisting that the bulging arsenal of Windows-specific malware was the result of being the juiciest target and thus the subject of the most malicious attention.
Even if you take them at their word here, that's still no excuse. Microsoft didn't slip and accidentally become an operating system monopolist. They relentlessly, deliberately, illegally pursued the goal of extinguishing every OS except their own. It's completely foreseeable that this dominance would make their products the subject of continuous attacks.
There's an implicit bargain that every monopolist makes: allow me to dominate my market and I will be a benevolent dictator who spends his windfall profits on maintaining product quality and security. Indeed, if we permit "wasteful competition" to erode the margins of operating system vendors, who will have a surplus sufficient to meet the security investment demands of the digital world?
But monopolists always violate this bargain. When faced with the decision to either invest in quality and security, or hand billions of dollars to their shareholders, they'll always take the latter. Why wouldn't they? Once they have a monopoly, they don't have to worry about losing customers to a competitor, so why invest in customer satisfaction? That's how Google can piss away $80b on a stock buyback and fire 12,000 technical employees at the same time as its flagship search product (with a 90% market-share) is turning into an unusable pile of shit:
https://pluralistic.net/2024/02/21/im-feeling-unlucky/#not-up-to-the-task
Microsoft reneged on this bargain from day one, and they never stopped. When the company moved Office to the cloud, it added an "analytics" suite that lets bosses spy on and stack-rank their employees ("Sorry, fella, Office365 says you're the slowest typist in the company, so you're fired"). Microsoft will also sell you internal data on the Office365 usage of your industry competitors (they'll sell your data to your competitors, too, natch). But most of all, Microsoft harvest, analyzes and sells this data for its own purposes:
https://pluralistic.net/2020/11/25/the-peoples-amazon/#clippys-revenge
Leave aside how creepy, gross and exploitative this is – it's also incredibly reckless. Microsoft is creating a two-way conduit into the majority of the world's businesses that insider threats, security services and hackers can exploit to spy on and wreck Microsoft's customers' business. You don't get more "too big to care" than this.
Or at least, not until now. Microsoft recently announced a product called "Recall" that would record every keystroke, click and screen element, nominally in the name of helping you figure out what you've done and either do it again, or go back and fix it. The problem here is that anyone who gains access to your system – your boss, a spy, a cop, a Microsoft insider, a stalker, an abusive partner or a hacker – now has access to everything, on a platter. Naturally, this system – which Microsoft billed as ultra-secure – was wildly insecure and after a series of blockbuster exploits, the company was forced to hit pause on the rollout:
https://arstechnica.com/gadgets/2024/06/microsoft-delays-data-scraping-recall-feature-again-commits-to-public-beta-test/
For years, Microsoft waged a war on the single most important security practice in software development: transparency. This is the company that branded the GPL Free Software license a "virus" and called open source "a cancer." The company argued that allowing public scrutiny of code would be a disaster because bad guys would spot and weaponize defects.
This is "security through obscurity" and it's an idea that was discredited nearly 500 years ago with the advent of the scientific method. The crux of that method: we are so good at bullshiting ourselves into thinking that our experiment was successful that the only way to make sure we know anything is to tell our enemies what we think we've proved so they can try to tear us down.
Or, as Bruce Schneier puts it: "Anyone can design a security system that you yourself can't think of a way of breaking. That doesn't mean it works, it just means that it works against people stupider than you."
And yet, Microsoft – whose made more widely and consequentially exploited software than anyone else in the history of the human race – claimed that free and open code was insecure, and spent millions on deceptive PR campaigns intended to discredit the scientific method in favor of a kind of software alchemy, in which every coder toils in secret, assuring themselves that drinking mercury is the secret to eternal life.
Access to source code isn't sufficient to make software secure – nothing about access to code guarantees that anyone will review that code and repair its defects. Indeed, there've been some high profile examples of "supply chain attacks" in the free/open source software world:
https://www.securityweek.com/supply-chain-attack-major-linux-distributions-impacted-by-xz-utils-backdoor/
But there's no good argument that this code would have been more secure if it had been harder for the good guys to spot its bugs. When it comes to secure code, transparency is an essential, but it's not a sufficency.
The architects of that campaign are genuinely awful people, and yet they're revered as heroes by Microsoft's current leadership. There's Steve "Linux Is Cancer" Ballmer, star of Propublica's IRS Files, where he is shown to be the king of "tax loss harvesting":
https://pluralistic.net/2023/04/24/tax-loss-harvesting/#mego
And also the most prominent example of the disgusting tax cheats practiced by rich sports-team owners:
https://pluralistic.net/2021/07/08/tuyul-apps/#economic-substance-doctrine
Microsoft may give lip service to open source these days (mostly through buying, stripmining and enclosing Github) but Ballmer's legacy lives on within the company, through its wildly illegal tax-evasion tactics:
https://pluralistic.net/2023/10/13/pour-encoragez-les-autres/#micros-tilde-one
But Ballmer is an angel compared to his boss, Bill Gates, last seen some paragraphs above, stealing the credit for MS DOS from Tim Paterson and billions of dollars from his co-founder Paul Allen. Gates is an odious creep who made billions through corrupt tech industry practices, then used them to wield influence over the world's politics and policy. The Gates Foundation (and Gates personally) invented vaccine apartheid, helped kill access to AIDS vaccines in Sub-Saharan Africa, then repeated the trick to keep covid vaccines out of reach of the Global South:
https://pluralistic.net/2021/04/13/public-interest-pharma/#gates-foundation
The Gates Foundation wants us to think of it as malaria-fighting heroes, but they're also the leaders of the war against public education, and have been key to the replacement of public schools with charter schools, where the poorest kids in America serve as experimental subjects for the failed pet theories of billionaire dilettantes:
https://www.ineteconomics.org/perspectives/blog/millionaire-driven-education-reform-has-failed-heres-what-works
(On a personal level, Gates is also a serial sexual abuser who harassed multiple subordinates into having sexual affairs with him:)
https://www.nytimes.com/2022/01/13/technology/microsoft-sexual-harassment-policy-review.html
The management culture of Microsoft started rotten and never improved. It's a company with corruption and monopoly in its blood, a firm that would always rather build market power to insulate itself from the consequences of making defective products than actually make good products. This is true of every division, from cloud computing:
https://pluralistic.net/2022/09/28/other-peoples-computers/#clouded-over
To gaming:
https://pluralistic.net/2023/04/27/convicted-monopolist/#microsquish
No one should ever trust Microsoft to do anything that benefits anyone except Microsoft. One of the low points in the otherwise wonderful surge of tech worker labor organizing was when the Communications Workers of America endorsed Microsoft's acquisition of Activision because Microsoft promised not to union-bust Activision employees. They lied:
https://80.lv/articles/qa-workers-contracted-by-microsoft-say-they-were-fired-for-trying-to-unionize/
Repeatedly:
https://www.reuters.com/technology/activision-fired-staff-using-strong-language-about-remote-work-policy-union-2023-03-01/
Why wouldn't they lie? They've never faced any consequences for lying in the past. Remember: the secret to Microsoft's billions is impunity.
Which brings me to Solarwinds. Solarwinds is an enterprise management tool that allows IT managers to see, patch and control the computers they oversee. Foreign spies hacked Solarwinds and accessed a variety of US federal agencies, including National Nuclear Security Administration (who oversee nuclear weapons stockpiles), the NIH, and the Treasury Department.
When the Solarwinds story broke, Microsoft strenuously denied that the Solarwinds hack relied on exploiting defects in Microsoft software. They said this to everyone: the press, the Pentagon, and Congress.
This was a lie. As Renee Dudley and Doris Burke reported for Propublica, the Solarwinds attack relied on defects in the SAML authentication system that Microsoft's own senior security staff had identified and repeatedly warned management about. Microsoft's leadership ignored these warnings, buried the research, prohibited anyone from warning Microsoft customers, and sidelined Andrew Harris, the researcher who discovered the defect:
https://www.propublica.org/article/microsoft-solarwinds-golden-saml-data-breach-russian-hackers
The single most consequential cyberattack on the US government was only possible because Microsoft decided not to fix a profound and dangerous bug in its code, and declined to warn anyone who relied on this defective software.
Yesterday, Microsoft president Brad Smith testified about this to Congress, and promised that the company would henceforth prioritize security over gimmicks like AI:
https://arstechnica.com/tech-policy/2024/06/microsoft-in-damage-control-mode-says-it-will-prioritize-security-over-ai/
Despite all the reasons to mistrust this promise, the company is hoping Congress will believe it. More importantly, it's hoping that the Pentagon will believe it, because the Pentagon is about to award billions in free no-bid military contract profits to Microsoft:
https://www.axios.com/2024/05/17/pentagon-weighs-microsoft-licensing-upgrades
You know what? I bet they'll sell this lie. It won't be the first time they've convinced Serious People in charge of billions of dollars and/or lives to ignore that all-important maxim, "When someone tells you who they are and you get fooled again, shame on you."
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/06/14/patch-tuesday/#fool-me-twice-we-dont-get-fooled-again
#pluralistic#microsoft#infosec#visual basic#ai#corruption#too big to care#patch tuesday#solar winds#monopolists bargain#eternal blue#transparency#open source#floss#oss#apts
278 notes
·
View notes
Text
Hi there’s a tornado in my area rn but I’m spiteful like that. Random tsams/eaps headcanons be upon ye
Ruin still does those little audio log diaries. It helps manage his overflowing memory storage (read: old age = more memories to store) without compressing data files.
Bloodmoon sleeps with dog toys. Otherwise, they’d probably chew through whatever bedding material they had chosen that night. This was Ruin’s idea.
Eclipse can’t sleep with lights on in a room. Ruin can’t sleep without a light. The makeshift solution is a sleeping mask for Eclipse, but their actual compromise is a star projector.
Eclipse has to know where everyone is most of the time, especially after Charlie came into the picture. This is usually done with cameras and tracking via fazbear systems, but it’s an issue he has to work on, as it’s just a method to make him feel better about security now that there are people he cares about. At least one person has commented on there being a new nightguard.
Dark sun finds thrillers tacky, and prefers thought-provoking mysteries, bonus points for romance.
Most of them carry some kind of sanitizing wipe packet. For daycare attendants, these are for sticky messes and children. For those more familiar with tools, these are for tougher grime and are not suitable for sensitive (children’s) skin. Solar has both.
The eclipses (Eclipse, Solar, Ruin) are the most prone to damaging their rays. Eclipse sometimes hits doorways and doesn’t bother to fix cracked rays. Ruin is small enough for humans to reach his head. Solar peels the paint off of his. All three will pull or squeeze their rays in times of extreme stress, to varying degrees. Lunar is an exception for lack of rays. (Similarly, Sun fidgets with his rays, which is the source of this trait.)
While there are exceptions, Suns prefer tactile stimulation, Moons auditory, and Eclipses have no strong preference. Earth likes social interaction.
Animatronics have personalized UI that makes sense to them, which serves as their access point to their internal folders, like memory files, downloaded items, and executable programs. Bots that share an operating system/“brain” have the same UI. Diagnostics, software updates, and safety modes all require additional hardware (computers, parts and service devices, fazwrenches) to complete. Mindscapes are in AI chips, and multiple AIs in one mindscape happen when multiple AIs share the same operating system. Visual feed can be projected onto other screens with HDMI cables and vice versa, which can sometimes show that bot’s UI depending on what it is. For a more direct example of this think of the battery and blue borders you see in Security breach when Gregory is hiding inside Freddy.
Safety mode disconnects that bot from the Fazbear Ent. local network, meaning no tracking, no communication via local networks (which generally aren’t private anyway, most bots with access to phones prefer those), and no access to files that aren’t stored in that bot’s drive. This is meant to isolate a bot’s systems from the main network in case of a security breach (hah), make transportation of bots between locations easier, and make maintenance a smoother affair as there is no outside interference during the process. For the bots themselves, this is the equivalent of turning off your phone and going outside I mean focusing only on what’s in front of you instead of what’s going on in your area/social network. It’s possible to be stuck in safety mode. Depending on how much of a bot’s system relies on Fazbear Ent. Networks to function (such as a bot’s memory being stored in a Cloud, which is also ill advised between the bots themselves,) this can be mean a temporary personality/memory reset until those files get reconnected again. Bots do not need to be connected to the Fazbear ent networks to function, but it generally makes access to software updates easier due to being recognized as a company entity. It is possible for a private network to exist, but it’s considered foreign by Fazbear systems and can be more trouble than they’re worth. Moon and Eclipse have private networks shared with close friends and family for different purposes. Moon’s is mostly for emergency backups, and Eclipse’s is for security.
Animatronic’s memories are stored in the hard drives in their bodies. It’s possible to offload memory files into networks (Cloud) or external storage systems. If another bot had access to these clouds or external storages, they could experience the memories stored in them. Memory files include visual and auditory data, like a movie. AI/personality chips are the equivalent of a soul in that the AI is the product of a learning AI having experienced environments that supplied them information about the world AKA an Ai that developed a personality beyond their base programming, but they do not carry memories. For example, Eclipse V3-V4 is an Eclipse AI given incomplete memories, creating a disconnect in the AI’s learned behaviors and what it perceives as the source of that behavior, resulting in an incomplete backup. Backups are static/unchanging copies of integral memory files and the accompanying AI (As is in the moment that they are backed up.) Backups need to be updated as the animatronic it’s for develops.
#go easy on me I only have basic knowledge of computer stuff#quirky headcanons#tsams#eaps#I’m also halfway through a sociology class so take the AI one with a grain of salt#hopefully this makes sense
25 notes
·
View notes
Note
Hi there, Love your work! I'm also doing stuff in Unreal and it feels like it's rarer to find other indie devs using it. I love how clean all your UI feels, and UI is something I seem to really struggle with.
Do you have any recommendations for workflows / tips / sources etc for getting better at UI?
Also I'd love to know more about the material / shader workflow for your latest post if you have more information anywhere.
Thanks :)
Hello there! Thank you!! I hope you don't mind me answering publicly as I feel like some people might be interested in the answer!
I really appreciate your UI (User Interface for those not knowing the acronym) compliment as it's something I've spent a long time working on and specializing in, in my career as a software engineer. UI/UX often goes completely unacknowledged or taken for granted even though it takes a lot of time and hard work to create and develop. In the engineering world I frequently had to advocate for and explain user experiences to those who didn't have as deep of an appreciation for UI or a very sophisticated understanding of why a good, visually appealing user experience makes, or on the flip side, can break everything. I think it's a very challenging, overwhelming topic to grasp and communicate, but just by being interested in it you're already way ahead!
There's a lot going on with UI. From visuals to knowing common design elements to successfully conveying a story to the user to implementation to testing to designing for accessibility to animation and I probably didn't cover everything with that run-on sentence. There's frontend engineers out there whose role is solely to maintain and improve UI component libraries for companies. And that's without throwing games, whose UIs are all uniquely visually tailored to their experiences, into the mix... I could keep going on about this honestly, but I'll get to what I think you can do personally! 1. Learn about common design patterns. What's a toast? What's pagination? What's a card? Little things like that. These apply to all software UI/UX, including video games- and knowing these off the top of your head will make it so much easier for you to invent your own UI designs and patterns.
2. Study the UI in the everyday applications you interact with. Step through menus and think about how you got from point A to point B. Take a moment to think about the why someone put a button where they did. Study the UI in your favorite video games, too! Take a lot of notes on what you think works really well and what you think doesn't. And also there's online resources that are great for inspiration. I personally spend a lot of time on the Game UI Database. - https://dribbble.com/ - https://www.gameuidatabase.com/ 3. Don't be afraid to start with basic sketches or even just simply representing everything with grey boxes. All my UI starts out as really crappy sketches on paper, or tablet sketches on top of screenshots. Visualize your ideas and then keep iterating on them until you've got something. For example, I went from this:

To this. (And come to think of it I might actually still want to make those cooler looking buttons in my sketch) 4. Break everything out into pieces and individual components. A good UI is made up of building blocks that you can reuse all over the place. That's how it stays consistent and also saves you a lot of stress when you need to go in and update components. Instead of a million different looking UI pieces, you just have to update the one! These individual components will make up your very own UI Component Library, which will be the standardized design system and source of reusable components for your project. This also applies to your visual elements that don't do anything (like I personally have a whole mini library of diamond and star shapes that I reuse everywhere).
For reference, here's a breakdown I made of my Inventory UI. On the right, I've labeled most of the individual components, and you might be able to see how I'm reusing them over and over again in multiple places.
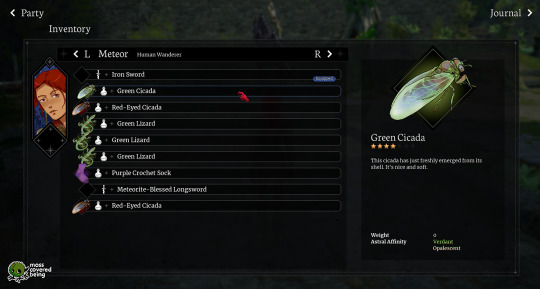
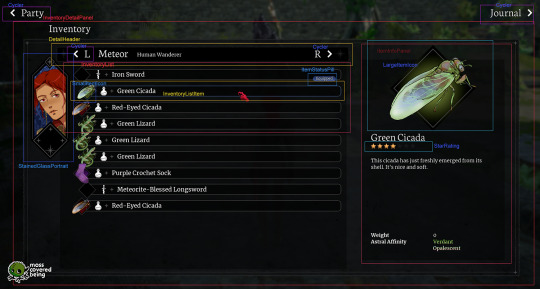
5. Spend some time listening to designers talk, maybe befriend some designers! Many of them have an unique, interesting view of the world and how we interact with it even beyond just software. Their perspectives will inform yours.
6. Test your UI on users whenever you can. Get feedback from others. This is the best way for you to see what works and what doesn't. As game devs we spend so much time with our games it's easy for us to lose sight of the full picture.
7. Be patient and don't give up. Continue to be open to expanding your knowledge. These UI skills take time to develop. I personally am still learning even after like 10 years of doing it. Coming up with the visual elements is very challenging for me and I spend a lot of time rearranging things in photoshop before I actually start coding anything at all in Unreal.
Whew, that was a lot, but I hope that gives you some thoughts and a place to start!
I don't have any posts out there about Blender/Unreal shader workflows right now, but I'll consider making another post sometime soonish. I appreciate you asking and you're welcome! :)
23 notes
·
View notes
Text

Verden Technology is a Software projects sourcing company in India providing cost-efficient turnkey solutions with an offshore development team.
Visit now - https://verdentechnology.com/software-project-subcontracting/
0 notes
Text
more on art production ~under capitalism~
reading Who Owns This Sentence?, a very engaging and fiercely critical history of the concept of copyright, and it's pretty fire. there's all sorts of fascinating intricacies in the way the notion of IP formed around the world (albeit so far the narrative has mainly focused on Europe, and to a limited extent China), and the different ideologies that justified the types of monopolies that it granted. the last chapter i read skewers the idea that the ability to exploit copyright and patents is what motivates the writing of books and research/invention, and I'll try and pull out the shape of the argument tomorrow. so far I'm only up to the 18th century; I'm looking forward to the rest of their story of how copyright grew from the limited forms of that period into the monster it is today.
it's on libgen if you wanna read it! i feel like the authors would be hypocrites to object :p
it is making me think about the differences between the making of books and other media, from (since this has been rattling around my head lately) an economic angle...
writing books, at least in the case of fiction is usually done on a prospective, spec-work kind of basis (you write your novel with no guarantee it will get published unless you're already an established author under contract). admittedly, a lot of us probably read books by authors who managed to 'make it' as professional authors and write full time - but this is not a lucrative thing to do and to make it work you need truly exceptional luck to get a major hit, or to be extremely prolific in things people want to read.
the films and games of the types most of us play are, by contrast, generally made by teams of salaried people - and thus do rarely get made without the belief it will be profitable. if you went on about your 'monetisation model' when writing a book, people would look at you funny and rightly so, but it's one of the first questions that gets asked when pitching a game.
open source software is a notable comparison here. a lot of it is done for its own sake without any expectation of profit, taking untold hours, but large free software projects tend to sprout foundations, which take donations (typically from companies that use the software) to pay for full time developers. mozilla, notably, gets a huge part of its funding from google paying for their search engine to be the default in Firefox; this in turn drives development of not just Firefox itself but also the Rust programming language (as discussed in this very enlightening talk by Evan Czaplicki). Blender is rightly celebrated as one of the best open source projects for its incredibly fast development, but they do have an office in amsterdam and a number of full time devs.
what money buys in regards to creative works is not motivation, but time - time to work on a project, iterate and polish and all that. in societies where you have to buy food etc. to survive, your options for existence are basically:
work at a job
own capital
rely on someone else (e.g. a parent or partner)
rely on state benefits if you can get them
beg
steal
if you're working at a job, this takes up a lot of your time and energy. you can definitely make art anyway, loads of people do, but you're much more limited in how you can work at it compared to someone who doesn't have to work another job.
so again, what money buys in art is the means of subsistence for someone, freeing them to work fully on realising a project.
where does the money come from that lets people work full time on art? a few places.
one is selling copies of the work itself. what's remarkable is that, when nearly everything can be pirated without a great deal of effort, it is still possible to do this to some degree - though in many ways the ease of digital copying (or at least the fear if it) has forced new models for purely digital creations, which either trade on convenience (streaming services) or in the case of games, find some way to enforce scarcity like requiring connection to a central server and including 'in-app purchases', where you pay to have the software display that you are the nebulous owner of an imaginary thing, and display this to other players. anyway, whichever exact model, the idea is that you turn the IP into capital which you then use to manufacture a product like 'legal copies', 'subscriptions' or 'accounts with a rare skin unlocked'.
the second is using the work to promote some other, more profitable thing - merchandising, an original work, etc. this is the main way that something like anime makes money (for the production committee, if not the studio) - the anime is, economics-wise, effectively an ad for its own source manga, figurines, shirts etc. the reason why there is so much pro media chasing the tastes of otaku is partly because otaku spend a lot on merch. (though it's also because the doujin scene kind of feeds into 'pro' production)
the third is some kind of patronage relationship, notably government grants, but also academic funding bodies, or selling commissions, or subscriptions on a streaming platform/patreon etc.
grants are how most European animated films are funded, and they often open with the logos of a huge list of arts organisations in different countries. the more places you can get involved, the more funds you can pull on. now, instead of working out how to sell your creation to customers who might buy a copy, under this model you need to convince funding bodies that it fits their remit. requesting grants involves its own specialised language.
in general the issue with the audience patronage model is that it only really pays enough to live on if you're working on a pretty huge scale. a minority make a fortune; the vast majority get a pittance at most, and if they do 'make it', it takes years of persistence.
the fourth is, for physical media, to sell an original. this only works if you can accumulate enough prestige, and the idea is to operate on extreme scarcity. the brief fad of NFTs attempted to abstract the idea of 'owning' an original from the legal right to control the physical object to something completely nebulous. in practice this largely ended up just being a speculative bubble - but then again, a lot of the reason fine art is bought and sold for such eye watering sums is pretty much the same, it's an arbitrary holder of an investment.
the fifth is artworks which are kind of intrinsically scarce, like live performances. you can only fit so many people in the house. and in many cases people will pay to see something that can be copied in unique circumstances, like seeing a film at a cinema or festival - though this is a special case of selling copies.
the sixth is to sell advertising: turn your audience into the product, and your artwork into the bait on the hook.
the alternative to all of these options is unpaid volunteer work, like a collab project. the participants are limited to the time and energy they have left after taking care of survival. this can still lead to great things, but it tends to be more unstable by its nature. so many of these projects will lose steam or participants will flake and they'll not get finished - and that's fine! still, huge huge amounts of things already get created on this kind of hobby/indie/doujin basis, generally (tho not always) with no expectation of making enough money to sustain someone.
in every single one of these cases, the economic forces shape the types of artwork that will get made. different media are more or less demanding of labour, and that in turn shapes what types of projects are viable.
books can be written solo, and usually are - collaborations are not the norm there. the same goes for illustrations. on the other hand, if you want to make a hefty CRPG or an action game or a feature length movie, and you're trying to fit that project around your day job... i won't say it's impossible, I can think of some exceptional examples, but it won't be easy, and for many people it just won't be possible.
so, that's a survey of possibilities under the current regime. how vital is copyright really to this whole affair?
one thing that is strange to me is that there aren't a lot of open source games. there are some - i have memories of seeing Tux Racer, but a more recent example would be Barotrauma (which is open source but not free, and does not take contributions from outside the company). could it work? could you pay the salaries of, say, 10 devs on a 'pay what you can' model?
it feels like the only solution to all of this in the long run is some kind of UBI type of thing - that or a very generous art grants regime. if people were free to work on what they wanted and didn't need to be paid, you wouldn't have any reason for copyright. the creations could be publicly archived. but then the question i have is, what types of artwork would thrive in that kind of ecosystem?
I've barely talked about the book that inspired this, but i think it was worth the trouble to get the contours of this kind of analysis down outside my head...
20 notes
·
View notes
Text
The damage the Trump administration has done to science in a few short months is both well documented and incalculable, but in recent days that assault has taken an alarming twist. Their latest project is not firing researchers or pulling funds—although there’s still plenty of that going on. It’s the inversion of science itself.
Here’s how it works. Three “dire wolves” are born in an undisclosed location in the continental United States, and the media goes wild. This is big news for Game of Thrones fans and anyone interested in “de-extinction,” the promise of bringing back long-vanished species.
There’s a lot to unpack here: Are these dire wolves really dire wolves? (They’re technically grey wolves with edited genes, so not everyone’s convinced.) Is this a publicity stunt or a watershed moment of discovery? If we’re staying in the Song of Ice and Fire universe, can we do ice dragons next?
All more or less reasonable reactions. And then there’s secretary of the interior Doug Burgum, a former software executive and investor now charged with managing public lands in the US. “The marvel of ‘de-extinction’ technology can help forge a future where populations are never at risk,” Burgum wrote in a post on X this week. “The revival of the Dire Wolf heralds the advent of a thrilling new era of scientific wonder, showcasing how the concept of ‘de-extinction’ can serve as a bedrock for modern species conservation.”
What Burgum is suggesting here is that the answer to 18,000 threatened species—as classified and tallied by the nonprofit International Union for Conservation of Nature—is that scientists can simply slice and dice their genes back together. It’s like playing Contra with the infinite lives code, but for the global ecosystem.
This logic is wrong, the argument is bad. More to the point, though, it’s the kind of upside-down takeaway that will be used not to advance conservation efforts but to repeal them. Oh, fracking may kill off the California condor? Here’s a mutant vulture as a make-good.
“Developing genetic technology cannot be viewed as the solution to human-caused extinction, especially not when this administration is seeking to actively destroy the habitats and legal protections imperiled species need,” said Mike Senatore, senior vice president of conservation programs at the nonprofit Defenders of Wildlife, in a statement. “What we are seeing is anti-wildlife, pro-business politicians vilify the Endangered Species Act and claim we can Frankenstein our way to the future.”
On Tuesday, Donald Trump put on a show of signing an executive order that promotes coal production in the United States. The EO explicitly cites the need to power data centers for artificial intelligence. Yes, AI is energy-intensive. They’ve got that right. Appropriate responses to that fact might include “can we make AI more energy-efficient?” or “Can we push AI companies to draw on renewable resources.” Instead, the Trump administration has decided that the linchpin technology of the future should be driven by the energy source of the past. You might as well push UPS to deliver exclusively by Clydesdale. Everything is twisted and nothing makes sense.
The nonsense jujitsu is absurd, but is it sincere? In some cases, it’s hard to say. In others it seems more likely that scientific illiteracy serves a cover for retribution. This week, the Commerce Department canceled federal support for three Princeton University initiatives focused on climate research. The stated reason, for one of those programs: “This cooperative agreement promotes exaggerated and implausible climate threats, contributing to a phenomenon known as ‘climate anxiety,’ which has increased significantly among America’s youth.”
Commerce Department, you’re so close! Climate anxiety among young people is definitely something to look out for. Telling them to close their eyes and stick their fingers in their ears while the world burns is probably not the best way to address it. If you think their climate stress is bad now, just wait until half of Miami is underwater.
There are two important pieces of broader context here. First is that Donald Trump does not believe in climate change, and therefore his administration proceeds as though it does not exist. Second is that Princeton University president Christopher Eisengruber had the audacity to suggest that the federal government not routinely shake down academic institutions under the guise of stopping antisemitism. Two weeks later, the Trump administration suspended dozens of research grants to Princeton totaling hundreds of millions of dollars. And now, “climate anxiety.”
This is all against the backdrop of a government whose leading health officials are Robert F. Kennedy Jr. and Mehmet Oz, two men who, to varying degrees, have built their careers peddling unscientific malarky. The Trump administration has made clear that it will not stop at the destruction and degradation of scientific research in the United States. It will also misrepresent, misinterpret, and bastardize it to achieve distinctly unscientific ends.
Those dire wolves aren’t going to solve anything; they’re not going to be reintroduced to the wild, they’re not going to help thin out deer and elk populations.
But buried in the announcement was something that could make a difference. It turns out Colossal also cloned a number of red wolves—a species that is critically endangered but very much not extinct—with the goal of increasing genetic diversity among the population. It doesn’t resurrect a species that humanity has wiped out. It helps one survive.
25 notes
·
View notes
Text
NEW DELHI (Reuters) -Global makers of surveillance gear have clashed with Indian regulators in recent weeks over contentious new security rules that require manufacturers of CCTV cameras to submit hardware, software and source code for assessment in government labs, official documents and company emails show.
The security-testing policy has sparked industry warnings of supply disruptions and added to a string of disputes between Prime Minister Narendra Modi's administration and foreign companies over regulatory issues and what some perceive as protectionism.
New Delhi's approach is driven in part by its alarm about China's sophisticated surveillance capabilities, according to a top Indian official involved in the policymaking. In 2021, Modi's then-junior IT minister told parliament that 1 million cameras in government institutions were from Chinese companies and there were vulnerabilities with video data transferred to servers abroad.
Under the new requirements applicable from April, manufacturers such as China's Hikvision, Xiaomi and Dahua, South Korea's Hanwha, and Motorola Solutions of the U.S. must submit cameras for testing by Indian government labs before they can sell them in the world's most populous nation. The policy applies to all internet-connected CCTV models made or imported since April 9.
"There's always an espionage risk," Gulshan Rai, India's cybersecurity chief from 2015 to 2019, told Reuters. "Anyone can operate and control internet-connected CCTV cameras sitting in an adverse location. They need to be robust and secure."
Indian officials met on April 3 with executives of 17 foreign and domestic makers of surveillance gear, including Hanwha, Motorola, Bosch, Honeywell and Xiaomi, where many of the manufacturers said they weren't ready to meet the certification rules and lobbied unsuccessfully for a delay, according to the official minutes.
In rejecting the request, the government said India's policy "addresses a genuine security issue" and must be enforced, the minutes show.
India said in December the CCTV rules, which do not single out any country by name, aimed to "enhance the quality and cybersecurity of surveillance systems in the country."
This report is based on a Reuters review of dozens of documents, including records of meetings and emails between manufacturers and Indian IT ministry officials, and interviews with six people familiar with India's drive to scrutinize the technology. The interactions haven't been previously reported.
Insufficient testing capacity, drawn-out factory inspections and government scrutiny of sensitive source code were among key issues camera makers said had delayed approvals and risked disrupting unspecified infrastructure and commercial projects.
"Millions of dollars will be lost from the industry, sending tremors through the market," Ajay Dubey, Hanwha's director for South Asia, told India's IT ministry in an email on April 9.
The IT ministry and most of the companies identified by Reuters didn't respond to requests for comment about the discussions and the impact of the testing policy. The ministry told the executives on April 3 that it may consider accrediting more testing labs.
Millions of CCTV cameras have been installed across Indian cities, offices and residential complexes in recent years to enhance security monitoring. New Delhi has more than 250,000 cameras, according to official data, mostly mounted on poles in key locations.
The rapid take-up is set to bolster India's surveillance camera market to $7 billion by 2030, from $3.5 billion last year, Counterpoint Research analyst Varun Gupta told Reuters.
China's Hikvision and Dahua account for 30% of the market, while India's CP Plus has a 48% share, Gupta said, adding that some 80% of all CCTV components are from China.
Hanwha, Motorola Solutions and Britain's Norden Communication told officials by email in April that just a fraction of the industry's 6,000 camera models had approvals under the new rules.
CHINA CONCERN
The U.S. in 2022 banned sales of Hikvision and Dahua equipment, citing national security risks. Britain and Australia have also restricted China-made devices.
Likewise, with CCTV cameras, India "has to ensure there are checks on what is used in these devices, what chips are going in," the senior Indian official told Reuters. "China is part of the concern."
China's state security laws require organizations to cooperate with intelligence work.
Reuters reported this month that unexplained communications equipment had been found in some Chinese solar power inverters by U.S. experts who examined the products.
Since 2020, when Indian and Chinese forces clashed at their border, India has banned dozens of Chinese-owned apps, including TikTok, on national security grounds. India also tightened foreign investment rules for countries with which it shares a land border.
The remote detonation of pagers in Lebanon last year, which Reuters reported was executed by Israeli operatives targeting Hezbollah, further galvanized Indian concerns about the potential abuse of tech devices and the need to quickly enforce testing of CCTV equipment, the senior Indian official said.
The camera-testing rules don't contain a clause about land borders.
But last month, China's Xiaomi said that when it applied for testing of CCTV devices, Indian officials told the company the assessment couldn't proceed because "internal guidelines" required Xiaomi to supply more registration details of two of its China-based contract manufacturers.
"The testing lab indicated that this requirement applies to applications originating from countries that share a land border with India," the company wrote in an April 24 email to the Indian agency that oversees lab testing.
Xiaomi didn't respond to Reuters queries, and the IT ministry didn't address questions about the company's account.
China's foreign ministry told Reuters it opposes the "generalization of the concept of national security to smear and suppress Chinese companies," and hoped India would provide a non-discriminatory environment for Chinese firms.
LAB TESTING, FACTORY VISITS
While CCTV equipment supplied to India's government has had to undergo testing since June 2024, the widening of the rules to all devices has raised the stakes.
The public sector accounts for 27% of CCTV demand in India, and enterprise clients, industry, hospitality firms and homes the remaining 73%, according to Counterpoint.
The rules require CCTV cameras to have tamper-proof enclosures, strong malware detection and encryption.
Companies need to run software tools to test source code and provide reports to government labs, two camera industry executives said.
The rules allow labs to ask for source code if companies are using proprietary communication protocols in devices, rather than standard ones like Wi-Fi. They also enable Indian officials to visit device makers abroad and inspect facilities for cyber vulnerabilities.
The Indian unit of China's Infinova told IT ministry officials last month the requirements were creating challenges.
"Expectations such as source code sharing, retesting post firmware upgrades, and multiple factory audits significantly impact internal timelines," Infinova sales executive Sumeet Chanana said in an email on April 10. Infinova didn't respond to Reuters questions.
The same day, Sanjeev Gulati, India director for Taiwan-based Vivotek, warned Indian officials that "All ongoing projects will go on halt." He told Reuters this month that Vivotek had submitted product applications and hoped "to get clearance soon."
The body that examines surveillance gear is India's Standardization Testing and Quality Certification Directorate, which comes under the IT ministry. The agency has 15 labs that can review 28 applications concurrently, according to data on its website that was removed after Reuters sent questions. Each application can include up to 10 models.
As of May 28, 342 applications for hundreds of models from various manufacturers were pending, official data showed. Of those, 237 were classified as new, with 142 lodged since the April 9 deadline.
Testing had been completed on 35 of those applications, including just one from a foreign company.
India's CP Plus told Reuters it had received clearance for its flagship cameras but several more models were awaiting certification.
Bosch said it too had submitted devices for testing, but asked that Indian authorities "allow business continuity" for those products until the process is completed.
When Reuters visited New Delhi's bustling Nehru Place electronics market last week, shelves were stacked with popular CCTV cameras from Hikvision, Dahua and CP Plus.
But Sagar Sharma said revenue at his CCTV retail shop had plunged about 50% this month from April because of the slow pace of government approvals for security cameras.
"It is not possible right now to cater to big orders," he said. "We have to survive with the stock we have."
7 notes
·
View notes
Text
Enter the FujoVerse™

Starting 2024's content creation journey with a bang, it's time to outline the principles behind the FujoVerse™: an ambitious (but realistic) plan to turn the web back into a place of fun, joy, and connection, where people build and nurture their own communities and software. (You can also read the article on my blog)
The Journey
As those who follow my journey with @bobaboard or read my quarterly newsletter (linked in the article) know, the used-to-be-called BobaVerse™ is a collection of projects I've been working on since 2020 while pondering an important question: how do we "fix" the modern social web?

Obviously the joyless landscape that is the web of today is not something a single person can fix. Still, I loved and owed the internet too much to see it wither.
After countless hours of work, I found 3 pillars to work on: community, software ownership and technical education.
Jump in after the cut to learn more about how it all comes together!
Community
Community is where I started from, with good reason! While social networks might trick us into thinking of them as communities, they lack the characteristics that researchers identify as the necessary base for "true community": group identity, shared norms, and mutual concern.
Today, I'm even more convinced community is a fundamental piece of reclaiming the web as a place of joy. It's alienating, disempowering, and incredibly lonely to be surrounded by countless people without feeling true connection with most of them (or worse, feeling real danger).

Software Ownership and Collaboration
As I worked with niche communities "software ownership" also became increasingly important to me: if we cannot expect mainstream tech companies to cater to communities at the margins, it follows that these communities must be able to build and shape their own software themselves.
Plenty of people have already discussed how this challenge goes beyond the tech. Among many, "collaboration" is another sticking point for me: effective collaboration requires trust and psychological safety, both of which are in short supply these days (community helps here too, but it's still hard).

Education (Technical and Beyond)
As I worked more and more with volunteers and other collaborators, however, another important piece of the puzzle showed itself: the dire state of educational material for non-professional web developers. How can people change the web if they cannot learn how to *build* the web?
(And yes, learning HTML and CSS is absolutely important and REAL web development. But to collaborate on modern software you need so much more. Even further, people *yearn* for more, and struggle to find it. They want that power, and we should give it to them.)
Once again, technical aspects aren't the only ones that matter. Any large-scale effort needs many skills that society doesn't equip us with. If we want to change how the web looks, we must teach, teach, TEACH! If you've seen me put so much effort into streaming, this is why :)
And obviously, while I don't go into them in this article, open source software and decentralized protocols are core to "this whole thing".

The Future
All of this said, while I've been working on this for a few years, I've struggled to find the support I need to continue this work. To this end, this year I'm doing something I'm not used to: producing content, gaining visibility, and putting my work in front of the eyes of people that want to fight for the future of the web.
This has been a hard choice: producing content is hard and takes energy and focus away from all I've been doing. Still, I'm committed to doing what it takes, and (luckily) content and teaching go hand in hand. But the more each single person helps, the less I need to push for wide reach.
If you want to help (and read the behind the scenes of all I've been working on before everyone else), you can subscribe to my Patreon or to my self-hosted attempt at an alternative.

I deeply believe that in the long term all that we're building will result in self-sustaining projects that will carry this mission forward. After all, I'm building them together with people who understand the needs of the web in a way that no mainstream company can replicate.
Until we get there, every little bit of help (be it monetary support, boosting posts, pitching us to your friends, or kind words of encouragement and support) truly matters.
In exchange, I look forward to sharing more of the knowledge and insights I've accrued with you all :)

And once again, to read or share this post from the original blog, you can find it here.
#bobaboard#fujoguide#freedom of the web#decentralized protocols#community#social networks#the great content creationing of 2024
88 notes
·
View notes
Text
#WageCageLocations













To proceed with generating or acquiring maps of underground tunnels or systems for 1183 Western Ave S, Los Angeles, CA, here’s a detailed guide you can follow:
Access Public Records
Contact Local Authorities: Reach out to the Los Angeles Department of Public Works or the Bureau of Engineering. They maintain maps and schematics of underground utilities and tunnel systems.
Website: LA Public Works
Phone: 311 (or 213-473-3231 outside Los Angeles)
Request Public Records: Submit a Public Records Act (PRA) request to obtain detailed maps of underground utilities or tunnels.
Use Geospatial Tools
Google Earth Pro:
Download Google Earth Pro (free) from here.
Search the address and explore its 3D and historical imagery layers.
Overlay city planning or utility map data if available.
ArcGIS:
Use GIS mapping software such as ArcGIS to access local underground data layers.
Some public libraries or universities provide free access to ArcGIS.
USGS Resources:
Check the U.S. Geological Survey (USGS) for geospatial data in the area: USGS Website.
Search their databases for subsurface or geological maps.
Hire Professionals
Geophysical Survey Services: Companies offering ground-penetrating radar (GPR) services can map underground tunnels, pipelines, and utilities. Examples:
GSSI (Ground Penetrating Radar Systems, Inc.)
Local geotechnical or engineering firms.
Surveying Experts: Licensed surveyors can create precise subsurface maps.
Research Historical and Urban Planning Data
Libraries and Archives:
Visit local archives or libraries like the Los Angeles Public Library. They often have historical maps and documents.
California Historical Society:
Explore their archives for historical records of tunnels or underground systems.
Collaborate with Open-Source Projects
OpenStreetMap:
Check OpenStreetMap for user-contributed data on the area.
Subterranean Mapping Communities:
Join forums or communities interested in urban exploration (e.g., Reddit's r/urbanexploration).
Final Steps
Once you've gathered relevant data, you can use tools like AutoCAD or GIS software to compile your maps. If you'd like further help with interpreting or organizing data, feel free to ask!
To proceed with generating or acquiring maps of underground tunnels or systems for 1183 Western Ave S, Los Angeles, CA, here’s a detailed guide you can follow:
Access Public Records
Contact Local Authorities: Reach out to the Los Angeles Department of Public Works or the Bureau of Engineering. They maintain maps and schematics of underground utilities and tunnel systems.
Website: LA Public Works
Phone: 311 (or 213-473-3231 outside Los Angeles)
Request Public Records: Submit a Public Records Act (PRA) request to obtain detailed maps of underground utilities or tunnels.
Use Geospatial Tools
Google Earth Pro:
Download Google Earth Pro (free) from here.
Search the address and explore its 3D and historical imagery layers.
Overlay city planning or utility map data if available.
ArcGIS:
Use GIS mapping software such as ArcGIS to access local underground data layers.
Some public libraries or universities provide free access to ArcGIS.
USGS Resources:
Check the U.S. Geological Survey (USGS) for geospatial data in the area: USGS Website.
Search their databases for subsurface or geological maps.
Hire Professionals
Geophysical Survey Services: Companies offering ground-penetrating radar (GPR) services can map underground tunnels, pipelines, and utilities. Examples:
GSSI (Ground Penetrating Radar Systems, Inc.)
Local geotechnical or engineering firms.
Surveying Experts: Licensed surveyors can create precise subsurface maps.
Research Historical and Urban Planning Data
Libraries and Archives:
Visit local archives or libraries like the Los Angeles Public Library. They often have historical maps and documents.
California Historical Society:
Explore their archives for historical records of tunnels or underground systems.
Collaborate with Open-Source Projects
OpenStreetMap:
Check OpenStreetMap for user-contributed data on the area.
Subterranean Mapping Communities:
Join forums or communities interested in urban exploration (e.g., Reddit's r/urbanexploration).
Final Steps
Once you've gathered relevant data, you can use tools like AutoCAD or GIS software to compile your maps. If you'd like further help with interpreting or organizing data, feel free to ask!
Here is a detailed prompt you can use for another AI or mapping tool capable of generating maps and schematics of underground tunnel systems:
Prompt for AI Map Generator:
"Generate a detailed map and schematic of the underground tunnel systems, utility lines, and infrastructure at and around the location 1183 Western Ave S, Los Angeles, CA. The map should include the following details:
Subsurface Layers:
Sewer systems, drainage systems, and stormwater pipelines.
Electrical, gas, and water utility lines.
Any known historical or abandoned tunnels.
Proximity:
Cover an area with a radius of 1 mile from the given location.
Highlight all connections to adjacent buildings and structures.
Visualization:
Provide both 2D and 3D views of the underground systems.
Use different colors and layers for various types of infrastructure (e.g., blue for water lines, yellow for gas lines, etc.).
Include a legend for easy identification of systems.
Additional Features:
Annotate points of interest (e.g., access points, manholes, maintenance tunnels).
Show depth levels for each layer (e.g., sewer system at 15 feet, utility lines at 10 feet).
Overlay the map with the above-ground street grid for reference.
Data Integration:
Incorporate open-source geospatial data, city planning maps, and historical records if available.
Highlight discrepancies between historical and current data.
Output Formats:
Provide the map in standard formats like GeoTIFF, DWG (AutoCAD), and PDF for versatility.
Include a .KMZ file for visualization in Google Earth."
This prompt provides clear instructions and context for generating a comprehensive underground map. Use it with AI tools like GIS-enabled platforms, geospatial mapping AIs, or simulation software. Let me know if you need adjustments or more guidance!






7 notes
·
View notes